One might assume it would be common practice within every IT department for there to be a centralized source of truth to easily lookup the primary contact for every IT asset (i.e. network range, hostname, IP address, or domain name).
This person, or group of people, is typically referred to as the “Responsible Person” (RP for short), who may be contacted in each of the following instances:
- To decide if a testing, QA, or unused legacy system must be Internet-accessible, or if it can be safely disabled or externally firewalled off.
- To receive public vulnerability disclosure reports, manage rapid security patch deployments, or handle incident response.
- To alert when anomalous network traffic is seen originating to or from a particular system.
- To alert for when a website is buggy, has become inoperable, performance is slowed, etc.
- To obtain penetration test permission from and to coordinate appropriate scheduling.
- To be responsible for managing system level accounts and access control.
For all these issues and many more, when it comes to attack surface management and IT in general, being able to quickly identify the RP and finding out how to reach them is invaluable. This is especially true in emergency situations like a data breach, when zero-day exploits are reported in the wild, or system performance has been degraded. Unfortunately, such RP systems are not often seen in practice, but every incident responder and IT manager would agree that it’s a really good idea. In fact, for the last 20 years, I’ve never heard anyone disagree.
For a little bit of fun Internet history, there’s actually an obscure and rarely used protocol (RFC 1183) within DNS that discusses RP records. This RFC protocol specifies the mailbox of the person responsible for a host and domain record. If you’ve never seen or heard of this RFC before, don’t worry, often even the most experienced systems and DNS admins are also unfamiliar. I only happen to know about it because when I worked at Yahoo (circa 2000), they used RP records in DNS to map hosts to employees. I used those RP records to report vulnerabilities I discovered to the system owner.

Making matters just that much trickier, a single asset could and probably should have multiple RPs, each with an independent function. Ideally, you want to contact the right person to solve a particular problem, as not all issues can be resolved by any one person, team, or even department. As an example, let’s lay out Responsible Person (RP) by function:
Business: Responsible for business-level decisions about the asset, such as feature release timing, sets SLAs, branding, promotional offerings, etc
Network: Responsible for the network on which the asset is connected. This includes configuring IP-addresses, hostnames, and managing how network traffic is routed through or around the asset.
System: Responsible for the core operating system, system patching and configuration, managing listening services, user account and access control, maintenance, backups, and disaster recovery.
Application: Responsible for the application (typically a web application) developed and deployed on top of the operating system. This includes release windows, software maintenance, etc.
Database: Responsible for the backend database, which is typically used by the resident web applications. Database management, data structure, patching & configuration, access control, etc.
Security: Responsible for establishing and ensuring security standards are applied to the asset, which includes receiving vulnerability disclosures, performing IPS monitoring, DFIR, penetration tests, etc. are included.
There are a few reasons why most companies don’t [yet] have an RP directory. The first and foremost is that most companies simply don’t [yet] have an asset inventory – also known as an attack surface map. No attack surface map, then no RP directory. Why this is the case has its own set of reasons, which I’ve previously discussed and what Bit Discovery is here to solve.
Secondly, collecting all the necessary RP contact information across an enterprise is extremely time consuming and manually intensive. Additionally, you probably don’t want this information being publicly accessible, which is likely why RFC 1183 didn’t see much adoption. This is where Bit Discovery has a few helpful features and that can lend a hand.
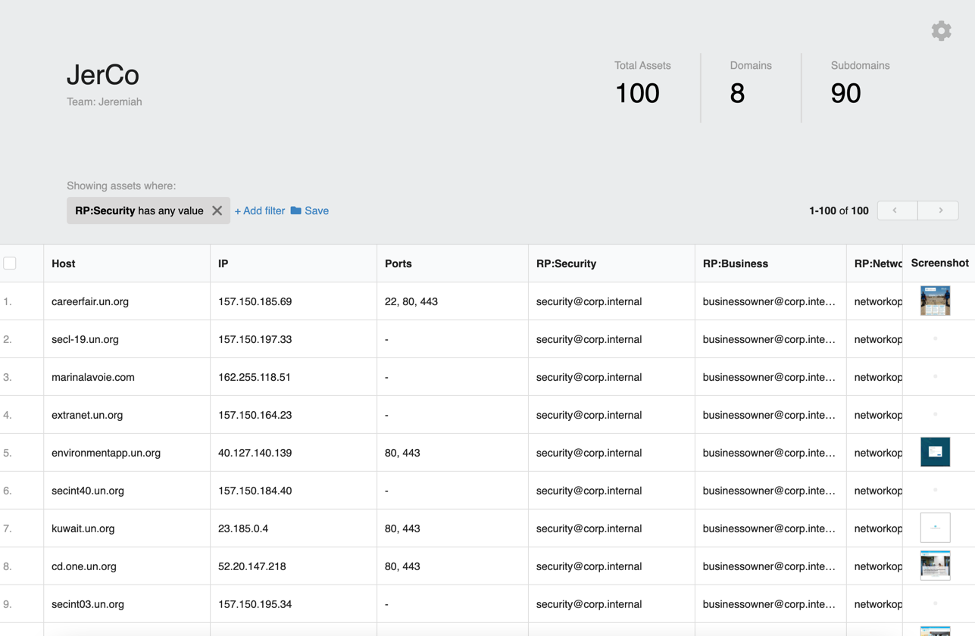
If you’re using Bit Discovery, then you already have an attack surface map – so that part is easily solved. Next, you can filter and sort assets by 100+ different columns of meta-data. Organize assets by hostname keyword, by network range, web server type, hosting country, domain name, software distribution and version, etc. Then, when you have a curated group of assets that you’re looking for, you can use the custom tagging feature to assign every asset within that group to particular RP (define them by name, email address, phone number, etc). Simple.
Then, whenever anyone needs to quickly identify the RP for an asset or identify all the assets an RP is responsible for – it’s all right there.