


There are many ways one can find shadow IT. Just look under someone’s desk, and you might find it that way. But if you want to find it at scale and see what’s on the public Internet, an Easter egg hunt under people’s desk just isn’t the way. Nor is searching in places you normally look. The following graphic attempts to explain why:
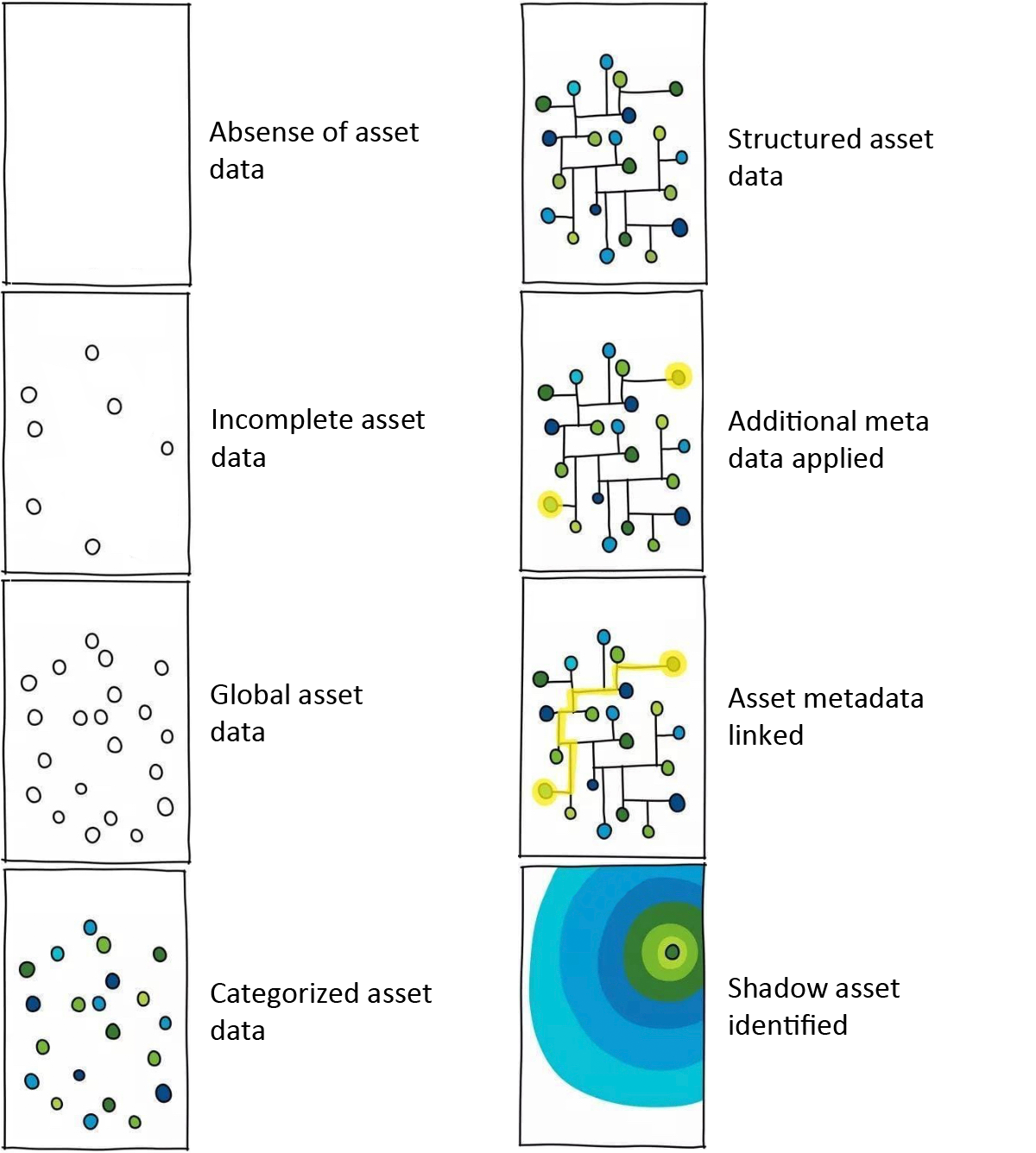
If you start with nothing it’s difficult to build up a list that is comprehensive. This can be done if you already know where to search, or if you are extremely good at hunting but it’s not easy. It’s a huge time sink, and more often than not you’ll miss a lot. Due to things like marketing teams who have their own budgets, dev teams, and infrastructure.
So the better way to find shadow IT- is to build up an asset list of everything everywhere. Then use the asset list to narrow in on things that might be correlated, by applying metadata to the asset and comparing that metadata. The simplest example would be looking for two domains with the same name but different top level domains (for instance, example.com and example.net). Metadata doesn’t have to be uniform though- some machines will have ports, and other won’t. Some machines will have websites, some won’t. You get the drift.
But when two or more things begin to look the same it becomes possible to start linking them together. However, you can’t build up a list of assets from scratch. You have to start with everything and narrow it down from that comprehensive list, to find things that correlate. That is part of why asset management is so tough – you can’t reliably do it yourself unless you know every piece of metadata for every asset everywhere, and can build correlations based on that knowledge.
That’s why Bit Discovery works so well – you can’t find shadow IT by doing real-time analysis unless there are already other linkages that point you to that domain. You need to find and use any form of metadata possible, to build up a massive data lake to build those correlations. That’s expensive and the main reason why traditional open source tools which do OSINT application/domain discovery- are rarely as thorough as this method when discovery is performed on enterprises of any meaningful size. Small companies, sure, but small companies can probably do it in 100 ways. It’s when the company starts growing, or when it’s not your company but a vendor/partner/customer- that you realize those tools simply aren’t the right answer if being thorough is important.






